문제 설명
전무로 승진한 라이언은 기분이 너무 좋아 프렌즈를 이끌고 특별 휴가를 가기로 했다.
내친김에 여행 계획까지 구상하던 라이언은 재미있는 게임을 생각해냈고 역시 전무로 승진할만한 인재라고 스스로에게 감탄했다.
라이언이 구상한(그리고 아마도 라이언만 즐거울만한) 게임은, 카카오 프렌즈를 두 팀으로 나누고, 각 팀이 같은 곳을 다른 순서로 방문하도록 해서 먼저 순회를 마친 팀이 승리하는 것이다.
그냥 지도를 주고 게임을 시작하면 재미가 덜해지므로, 라이언은 방문할 곳의 2차원 좌표 값을 구하고 각 장소를 이진트리의 노드가 되도록 구성한 후, 순회 방법을 힌트로 주어 각 팀이 스스로 경로를 찾도록 할 계획이다.
라이언은 아래와 같은 특별한 규칙으로 트리 노드들을 구성한다.
- 트리를 구성하는 모든 노드의 x, y 좌표 값은 정수이다.
- 모든 노드는 서로 다른 x값을 가진다.
- 같은 레벨(level)에 있는 노드는 같은 y 좌표를 가진다.
- 자식 노드의 y 값은 항상 부모 노드보다 작다.
- 임의의 노드 V의 왼쪽 서브 트리(left subtree)에 있는 모든 노드의 x값은 V의 x값보다 작다.
- 임의의 노드 V의 오른쪽 서브 트리(right subtree)에 있는 모든 노드의 x값은 V의 x값보다 크다.
아래의 예시를 확인해보자
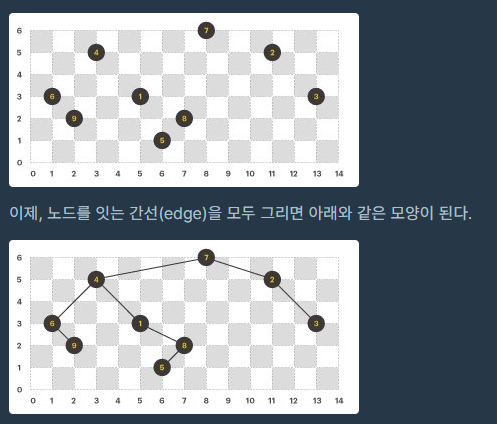
라이언의 규칙에 맞게 이진트리의 노드만 좌표 평면에 그리면 다음과 같다. (이진트리의 각 노드에는 1부터 N까지 순서대로 번호가 붙어있다.)
위 이진트리에서 전위 순회(preorder), 후위 순회(postorder)를 한 결과는 다음과 같고, 이것은 각 팀이 방문해야 할 순서를 의미한다.
- 전위 순회 : 7, 4, 6, 9, 1, 8, 5, 2, 3
- 후위 순회 : 9, 6, 5, 8, 1, 4, 3, 2, 7
다행히 두 팀 모두 머리를 모아 분석한 끝에 라이언의 의도를 간신히 알아차렸다.
그러나 여전히 문제는 남아있다. 노드의 수가 예시처럼 적다면 쉽게 해결할 수 있겠지만, 예상대로 라이언은 그렇게 할 생각이 전혀 없었다.
이제 당신이 나설 때가 되었다.
곤경에 빠진 카카오 프렌즈를 위해 이진트리를 구성하는 노드들의 좌표가 담긴 배열 nodeinfo가 매개변수로 주어질 때,
노드들로 구성된 이진트리를 전위 순회, 후위 순회한 결과를 2차원 배열에 순서대로 담아 return 하도록 solution 함수를 완성하자.
제한사항
- nodeinfo는 이진트리를 구성하는 각 노드의 좌표가 1번 노드부터 순서대로 들어있는 2차원 배열이다.
- nodeinfo의 길이는 1 이상 10,000 이하이다.
- nodeinfo[i] 는 i + 1번 노드의 좌표이며, [x축 좌표, y축 좌표] 순으로 들어있다.
- 모든 노드의 좌표 값은 0 이상 100,000 이하인 정수이다.
- 트리의 깊이가 1,000 이하인 경우만 입력으로 주어진다.
- 모든 노드의 좌표는 문제에 주어진 규칙을 따르며, 잘못된 노드 위치가 주어지는 경우는 없다.
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr

이진 트리(Binary Tree)
트리의 부모 노드가 최대 두 개의 자식 노드만을 가질 때 해당 트리를 '이진 트리'라고 부른다.
DFS 기반 탐색 알고리즘인
- 전위 순회(Preorder Traversal)
- 중위 순회(Inorder Traversal)
- 후위 순회(Postorder Traversal)
를 적용하여 이진 트리 전체 노드를 탐색할 수 있다.
이진 탐색 트리(Binary Search Tree)
이진 탐색 트리는 특정 조건을 만족하는 이진트리이다.
- 부모 노드의 왼쪽 노드는 부모 노드보다 작아야 한다.
- 부모 노드의 오른쪽 노드는 부모 노드보다 커야한다.
이진 탐색 트리는 말 그대로 이진 탐색에 트리의 개념이 더해진 것으로 특정 값을 탐색하는 것에 빠른 성능을 보인다.
*평균적으로 O(NlogN), 최악의 경우 O(N)

예를 들어 그림에서 '7'을 찾고 싶다면 Root(8)부터 탐색이 시작된다.
- '7'이 Root(8)보다 큰가 작은가? : 작으면 왼쪽(3)으로 이동
- '7'이 Node(3)보다 큰가 작은가? : 크면 오른쪽(6)으로 이동
- '7'이 Node(6)보다 큰가 작은가? : 크면 오른쪽(7)으로 이동
- '7'이 Node(7)의 값과 동일하다. 탐색 종료
풀이 코드
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
class Node
{
private:
int m_posX;
int m_value;
Node* m_left;
Node* m_right;
public:
Node(int posX, int value, Node* left, Node* right)
:m_posX(posX), m_value(value), m_left(left), m_right(right)
{
}
int GetPosX()
{
return m_posX;
}
int GetValue()
{
return m_value;
}
Node* GetLeft()
{
return m_left;
}
Node* GetRight()
{
return m_right;
}
void AddData(Node* newNode)
{
if (m_posX < newNode->GetPosX())
{
if (m_right == nullptr)
{
m_right = newNode;
}
else
{
m_right->AddData(newNode);
}
}
else
{
if (m_left == nullptr)
{
m_left = newNode;
}
else
{
m_left->AddData(newNode);
}
}
}
};
static void PrintPreOrder(Node* root, vector<int>* vec)
{
if (root == nullptr) return;
vec->push_back(root->GetValue());
PrintPreOrder(root->GetLeft(), vec);
PrintPreOrder(root->GetRight(), vec);
}
static void PrintPostOrder(Node* root, vector<int>* vec)
{
if (root == nullptr) return;
PrintPostOrder(root->GetLeft(), vec);
PrintPostOrder(root->GetRight(), vec);
vec->push_back(root->GetValue());
}
bool cmp(vector<int>& first, vector<int>& second)
{
return first[1] > second[1];
}
vector<vector<int>> solution(vector<vector<int>> nodeinfo)
{
int index = 1;
for (int i = 0; i < nodeinfo.size(); i++)
{
nodeinfo[i].push_back(index++);
}
sort(nodeinfo.begin(), nodeinfo.end(), cmp);
Node* root = new Node(nodeinfo[0][0], nodeinfo[0][2], nullptr, nullptr);
for (int i = 1; i < nodeinfo.size(); i++)
{
root->AddData(new Node(nodeinfo[i][0], nodeinfo[i][2], nullptr, nullptr));
}
vector<int> preOrderVec;
vector<int> postOrderVec;
PrintPreOrder(root, &preOrderVec);
PrintPostOrder(root, &postOrderVec);
vector<vector<int>> answer{ preOrderVec, postOrderVec };
return answer;
}
참고 사이트
[Algorithm] 이진 탐색 트리 (Binary Search Tree, BST) + 전위 중위 후위 순회
인트로 그래프의 탐색 방법으로 DFS와 BFS가 대표적이다. 트리는 특정 조건을 만족하는 그래프이다. 따라서 트리에 BFS와 DFS 탐색 알고리즘을 적용할 수 있다. 본 포스팅에선 DFS에 기반한 이진 트
kangworld.tistory.com
'프로그래밍 > Algorithm' 카테고리의 다른 글
| [프로그래머스 Programmers] 가장 긴 팰린드롬 (1) | 2023.09.19 |
|---|---|
| [백준 BAEKJOON] 1330번 두 수 비교하기 (0) | 2023.09.19 |
| [프로그래머스 Programmers] 하노이의 탑 (1) | 2023.09.07 |
| [프로그래머스 Programmers] 분수의 덧셈 (2) | 2023.09.06 |
| 동적 계획법(Dynamic Programming, DP) (0) | 2023.09.01 |




댓글