Hashtable 컬렉션은 값(value)뿐만 아니라 해시에 사용되는 키(Key)가 추가되어 빠른 검색 속도를 자랑한다. 따라서 검색 속도의 중요도에 따라 ArrayList 또는 Hashtable을 선택할지 결정한다.
Hashtable의 검색속도가 ArrayList에 비해 어떻게 빨라질 수 있는지 2개의 컬렉션에서 함께 제공하는 Remove 메서드를 예로 들어보자.
ArrayList.Remove의 경우
- 0번째 요소의 값과 Remove 인자의 값을 비교한다. 같으면 삭제하고 return 문을 수행한다.
- 1번째 단계에서 값을 찾기 못하면 그다음 요소의 값과 비교한다. 값이 같으면 삭제하고 return 문을 수행한다.
- 값을 찾을 때까지 위의 동작을 반복한다. 값이 ArrayList에 존재하지 않는 경우 전체 요소의 값을 열람할 수밖에 없다.
Hashtable.Remove의 경우
- 인자로 들어온 Key 값을 해시(hash)한다. 예를 들어 "key1" 문자열이 키 값인 경우 "key1".GetHashCode() 메서드를 호출한다.
- GetHashCode 메서드 호출의 결괏값은 정수다. 그 정수는 내부 데이터 저장소에 대해 곧바로 접근할 수 있는 인덱스로 사용된다. 따라서 값을 검색하는 과정 없이 곧바로 저장된 값의 위치를 알 수 있다.
- 해시에 해당하는 위치에 값이 있다면 삭제하고, 없다면 더는 추가적인 동작을 수행하지 않고 실행을 마친다.
이런 검색 과정의 차이를 빅-오 표기법(Big-O Notation)으로 나타내면 ArrayList는 O(n), Hashtable은 O(1)이 된다. 이를 토대로 컬렉션의 크기와 검색 속도의 관계를 단순하게 나타내면 다음과 같다.
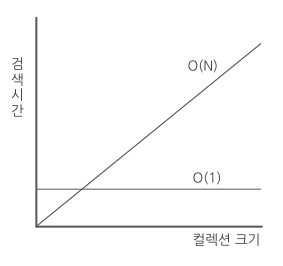
컬렉션에 담긴 항목 수가 많아질수록 Hashtable의 검색 속도가 ArrayList와 비교해서 더욱 빨라진다는 사실을 알 수 있다. 단지 그래프의 왼쪽 하단을 보면 컬렉션의 크기가 작을 때 O(n)의 성능이 더 좋은 것을 알 수 있다. 이 때문에 작은 크기의 컬렉션인 경우에는 ArrayList를 선택해도 무방하다.
예제 코드

Hashtable을 사용할 때 한 가지 주의할 점이 있다면 키 값이 중복되는 경우 Add 메서드에서 ArgumentException 예외가 발생하므로 중복 키에 주의를 기울여야 한다는 것이다. 또한 Hashtable은 ArrayList와 달리 키 값도 내부적으로 보관하고 있기 때문에 그만큼 추가적인 메모리가 사용된다. 게다가 키와 값이 모두 Object 타입으로 다뤄지기 때문에 박싱 문제가 발생한다. 타입을 명시하고 Dictionary를 사용하기를 권장한다.
'프로그래밍 > C#' 카테고리의 다른 글
| C# 명명된 인자(Named Arguments)와 선택적 인자(Optical Arguments) (20) | 2023.05.25 |
|---|---|
| C# 스레딩 (25) | 2023.05.24 |
| C# 컬렉션 - System.Collections.ArrayList (4) | 2023.05.22 |
| P/Invoke란 무엇인가? (48) | 2023.05.19 |
| C# 단정밀도(Single Precision), 배정밀도(Double Precision)에 대해서 (7) | 2023.05.11 |




댓글