해시 테이블(Hash Table)이란?
- 데이터의 삽입, 제거, 탐색이 모두 O(1)으로 매우 빠름
- 내부적으로 정렬되지 않음
- 저장할 데이터의 수보다 더 많은 공간이 필요
해싱(Hashing)
해시 테이블은 키를 해시 함수(Hash Function)에서 해싱(Hasing) 과정을 거쳐서 해시 테이블에 저장한다.
해시 함수로 알려진 수학 공식을 사용하여 가변 크기의 입력에서 고정 크기 출력을 생성하는 프로세스를 말한다.


- 해싱(hashing)
- 키(key)
- 해시함수(hash function)
- 해시 값(hash value)
Hash 예시
크기가 11인 해시 테이블에 5개 원소 (44, 13, 15, 8, 21) 저장

가변 크기 입력을 고정 크기 입력으로 바꾸기 위해서 임의의 숫자 11로 나머지 연산 수행
hashFunction(44) = 44 % 11= 0
hashFunction(13) = 13 % 11 = 2
hashFunction(15) = 15 % 11 = 4
hashFunction(8) = 8 % 11 = 8
hashFunction(21) = 21 % 11 = 10
Hash 충돌 상황과 해결방법
Hash를 구현할 때, 동일한 Hash Index를 가지게 되면 어떻게 해야 할까? (Hash 충돌)
아래와 같은 상황에서 원소 19, 30을 저장할 때,
이미 Hash Index가 존재한다. (Hash 충돌!)

- 체이닝(Chaining)
- 개방 주소(Open Addressing)
체이닝(Chaining)
같은 주소로 hashing 되는 원소들을 Linked list로 관리
원소를 삭제하거나 변경하는 작업이 상대적으로 간단하다.

동일 index에 대해서 데이터를 저장하는 자료구조를 Linked list가 아니라
Tree를 이용하여 저장해서 탐색(Search)의 성능을 높일 수 있다.
실제로, JDK 1.8의 경우에는 index에 노드가 8개 이하일 경우에는 Linked List를 사용하며, 그 이상으로 증가할 때는 Tree 구조로 데이터 저장 구조를 바꾸도록 되어있다.
개방 주소(Open Addressing)
개방 주소 기법에도 여러가지 방식이 존재한다.
- 선형 조사(Linear Probing)
- 이차원 조사(Quadratic Probing)
- 이중 해싱(Double hashing)
이 중에서 간단한 선형 조사 방식을 살펴보면, 비어있는 hash Index를 순차적으로 찾는다.
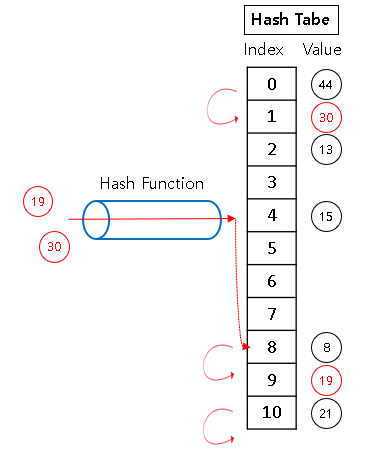
- 19를 입력했을 때, Hash Table [8]에 이미 '8'이 존재하기 때문에 다음 진 자리 탐색 -> Hash Table[9]에 입력
- 30을 입력했을 때, Hash Table [8]에 이미 '8'이 존재하기 때문에 다음 진 자리 탐색 -> Hash Table[9] -> Hash Table[10] -> Hash Table[0] -> Hash Table[1]에 입력
결론
사실 충돌이 찾으면 해시의 최대 장점인 Key를 통한 O(1)만에 value를 가져온다고 볼 수 없다.
따라서 충돌을 최소화하기 위해서는 Index Mapping 자체를 효율적으로 구현해야 한다.
해시 함수(Hash Function)의 종류 : MD1, MD4, MD5, SHS, SHA-1, HAS-160등
해시 테이블이 적합하지 않은 경우들
- 정렬된 데이터가 필요할 때
- 멀티미디어 데이터를 저장할 때
- 키의 길이가 길고 가변적이어서 키에 대한 사전 검색이 필요할 때
- 조건에 따라 데이터가 동적으로 변해야 할 때
- 데이터의 키가 유일하지 않을 때
참고 사이트
[해시] Hash란?
Hash란? 원소가 저장되는 위치가 원소 값에 의해 결정되는 자료구조 - 평균 상수 시간에 삽입, 검색, 삭제가 가능하다. - 매우 빠른 응답을 요구하는 상황에 유용 (Hash는 최소(최대) 원소를 찾는 것
zoosso.tistory.com
What is Hashing? - GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
www.geeksforgeeks.org
'프로그래밍 > Algorithm' 카테고리의 다른 글
| C# [백준 BAEKJOON] 11286번 절대값 힙 (0) | 2024.05.23 |
|---|---|
| C# [백준 BAEKJOON] 17219번 비밀번호 찾기 (0) | 2024.05.22 |
| C# [백준 BAEKJOON] 11279번 최대 힙 (0) | 2024.05.14 |
| C# [백준 BAEKJOON] 1927번 최소 힙 (0) | 2024.05.07 |
| C# [백준 BAEKJOON] 17087번 숨바꼭질 6 (0) | 2024.05.07 |




댓글